顧客リストやアンケート結果を扱う際、氏名データが「山田太郎」のようにスペース(区切り文字)無しで入力されていることはありませんか?
こうしたデータは、顧客管理システム(CRM)への登録や、DM(ダイレクトメール)の宛名作成時に、「氏」と「名」に分割する「データクレンジング(データの整形・正規化)」作業が必要になります。
しかし、何百、何千件ものデータを手作業で分割するのは、非常に時間がかかり、入力ミスの原因にもなります。
今回は、そのような手間のかかる作業を自動化し、効率的かつ正確なデータクレンジングを実現するスプレッドシートの活用法を、コピペで使えるサンプルと共にご紹介します。
無料配布:氏名分割(スペース自動判定)テンプレート
「名字」と「名前」の間にスペースがないデータを、関数とマスタを使って自動分割できるテンプレートを無料で配布しています。
複雑な関数を組む必要も、マスタをゼロから作る必要もありません。
【テンプレートに含まれるもの】
- 自動分割用の関数(LET, VLOOKUP等)設定済みシート
- 分割の基準となる「名氏(苗字)マスタ」リスト
- コピーしてすぐに使えるサンプルデータ
以下のフォームからテンプレートを受け取り、Step1の手順に沿って自社データで試してみてください。
自動分割の対象と条件
- 対象の氏名データは、氏と名の間に区切り(スペースなど)がないものとします。
- 分割可能な氏名データは、あらかじめ用意した[名氏マスタ]シートに登録されている名字(苗字)を対象とします。
- 対象の氏名データをスプレッドシート関数で、「氏」と「名」に自動で分割して表示させます。
解決フロー(設定手順)
設定は非常に簡単です。以下の2ステップで完了します。
Step1:事前準備
1.テンプレートの用意
ページ上部のフォームからダウンロードした「氏名分割スプレッドシート」を開き、ご自身のGoogleドライブに「コピーを作成」してください。
※このシートには、あらかじめ関数と名字マスタが設定されています。
2.対象データの用意
分割したい実際の氏名データ(ExcelまたはCSV形式など)を手元にご用意ください。
Step2:対象データの更新と確認
1. データの貼り付け
コピーしたスプレッドシートの[氏名分割]シートを開き、『氏名データ』(A列)の2行目以降に、お手持ちの対象データを貼り付け(上書き)します。
2. 分割結果の確認
データを貼り付けると即座に関数が実行され、B列に「氏」、C列に「名」が自動で表示されます。
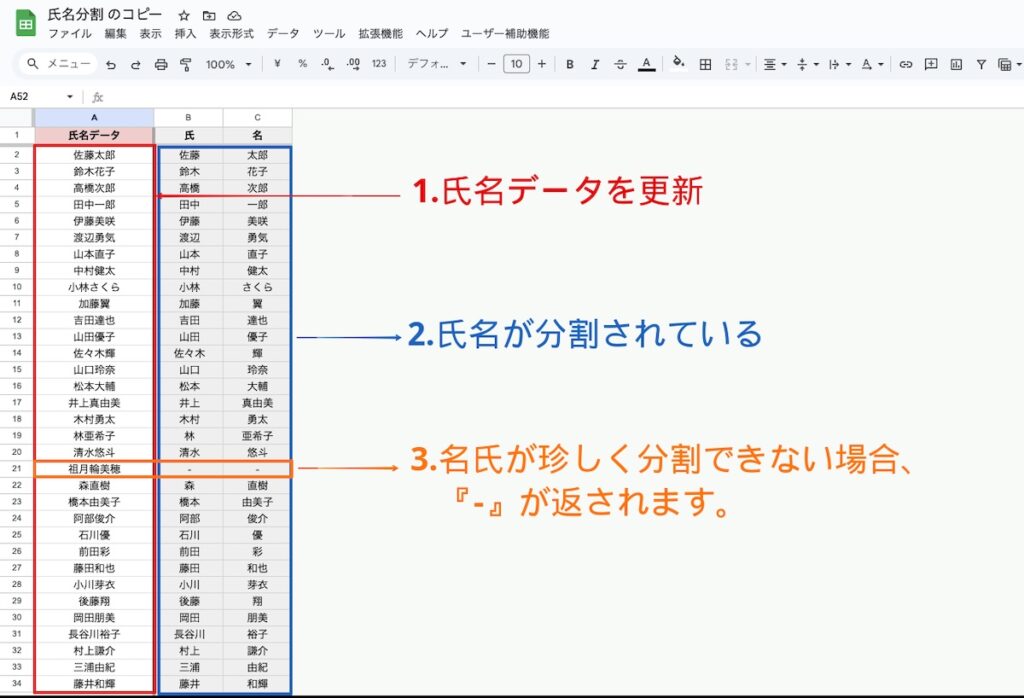
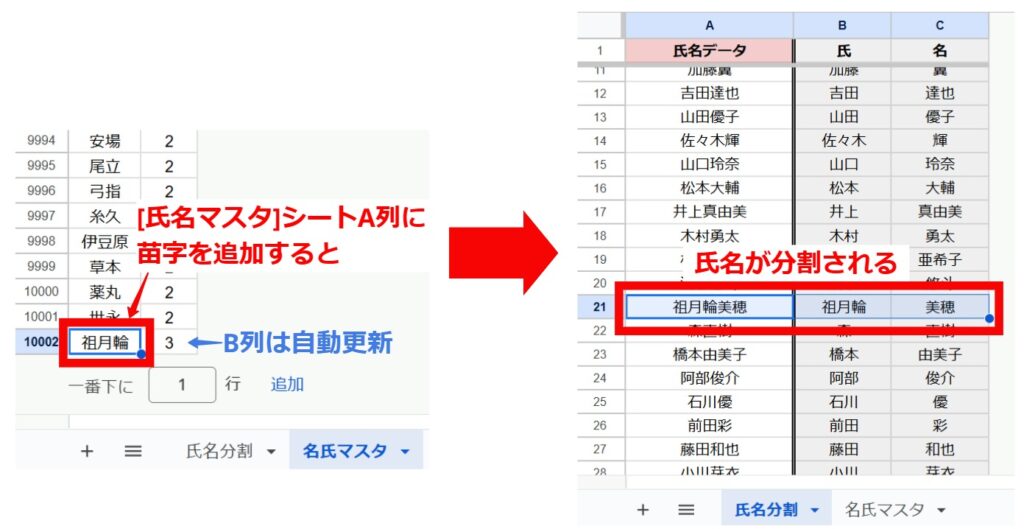
3. マスタのメンテナンス
一部分割できない氏名([名氏マスタ]に登録されていない名字)は、B列・C列に「-」(ハイフン)が返されます。
「-」が返された名字も、[名氏マスタ]シートのA列末尾へ追加登録することで、次回から正しく分割できるようになります。
コピペでOK!実際の関数
B列(氏)とC列(名)の1行目(見出しセル)には、以下の関数が設定されています。
▼ B1セル(氏を抽出)
=ARRAYFORMULA(
LET(
s, REGEXREPLACE($A:$A,"[ ]",""),
m, '名氏マスタ'!$A$2:$Z,
k, MATCH("氏",'名氏マスタ'!$1:$1,0),
IF(ROW($A:$A)=1,"氏",
IF(s="","",
IFNA(VLOOKUP(LEFT(s,4),m,k,FALSE),
IFNA(VLOOKUP(LEFT(s,3),m,k,FALSE),
IFNA(VLOOKUP(LEFT(s,2),m,k,FALSE),
IFNA(VLOOKUP(LEFT(s,1),m,k,FALSE),"-")))))
)
)
)▼ C1セル(名を抽出)
=ARRAYFORMULA(
IF(ROW(C1:C)=1,"名",
IF($A$1:$A="","",
IF($B$1:$B="-","-",REGEXREPLACE(REGEXREPLACE($A:$A,"[ ]",""),$B$1:$B,""))
)
)
)この自動分割では、複数の関数を組み合わせています。
「コピペで動くけれど、どういう仕組みなの?」という方のために、使用している主な関数を簡単にご紹介します。
1. LET関数
- 役割: 数式内で「変数(名前)」を定義できる関数です。複雑な数式をシンプルにし、可読性(読みやすさ)と処理速度を向上させます。
- 今回の使い方: s に「スペースを削除した氏名」、m に「名氏マスタの範囲」などと名前を付け、VLOOKUP 関数などでそれらを繰り返し使う際の記述を簡潔にしています。
- 関数の詳しい使い方は、こちらの記事をご確認ください。
2. ARRAYFORMULA関数
- 役割: 1つのセルに入力した数式を、指定した範囲の複数行にまとめて適用(自動コピー)する関数です。
- 今回の使い方: B1セルに入力しただけで、A列のデータがあるすべての行に対して分割処理を実行しています。
- 関数の詳しい使い方は、こちらの記事をご確認ください。
3. IF関数
- 役割: 「もし〇〇だったらA、そうでなければB」という条件分岐を作る、最も基本的な関数の一つです。
- 今回の使い方: 「1行目なら見出しを出す」「A列が空欄なら空欄にする」といった処理の制御に使っています。
- 関数の詳しい使い方は、こちらの記事をご確認ください。
4. REGEXREPLACE関数
- 役割: 「正規表現(せいきひょうげん)」というルールに基づき、特定の文字パターンを検索し、置き換えたり削除したりする関数です。
- 今回の使い方: REGEXREPLACE($A:$A,”[ ]”,””) として、氏名データに含まれる半角または全角スペースをすべて削除(空欄に置き換え)し、データを整形しています。
- 関数の詳しい使い方は、こちらの記事をご確認ください。
5. VLOOKUP関数
- 役割: 指定した「範囲(今回は[名氏マスタ])」から「検索したい値」を探し、対応するデータを取り出す関数です。
- 今回の使い方: 氏名の先頭から1〜4文字を取り出し、それが[名氏マスタ]に登録されているか(名字として存在するか)を調べています。
- 関数の詳しい使い方は、こちらの記事をご確認ください。
6. IFNA関数
- 役割: 「もし関数が#N/Aエラー(見つかりませんエラー)だったら、代わりにこの値を表示する」という指定ができる関数です。VLOOKUP関数と組み合わせて使われることが非常に多いです。
- 今回の使い方: VLOOKUPで名字(苗字)を検索した際、[名氏マスタ]に見つからないと#N/Aエラーが発生します。IFNAは、そのエラーをキャッチし、代わりに「次の検索(例:4文字で見つからなければ3文字を試す)」を実行させたり、最後まで見つからなかった場合に『-』(ハイフン)を表示させたりする役割を担っています。
まとめ
分割されていない氏名データを手動で修正しようとすると、非常に手間がかかり、ミスも発生しやすくなります。
本記事でご紹介したスプレッドシート関数(特にLET、ARRAYFORMULA、VLOOKUP、IFNAの組み合わせ)を用いた自動修正手法を活用することで、効率的かつ正確なデータクレンジングが実現できます。
[名氏マスタ]を一度整備してしまえば、今後の同様の作業時間を大幅に短縮できるはずです。
ぜひ、この「そのまま使える」スプレッドシートをご活用ください。
解説は以上です。
マスタの準備や関数の記述をスキップしたい方は、以下の配布テンプレートをご利用ください。
▶︎ ページ上部のフォームからテンプレートを受け取る(無料)
この記事の方法で解決できないケースが発生した場合は、【お問い合わせフォーム】からお気軽にご連絡ください。別途、最適な解決策をご提案いたします。
※Googleサービスは、Google LLC の商標であり、この記事はGoogleによって承認されたり、Google と提携したりするものではありません。