「顧客リストの電話番号の形式がバラバラ…」
「アンケートの自由回答から特定のキーワードを含むセルだけ見つけたい…」
Googleスプレッドシートでこのようなデータ整理に時間がかかっていませんか?
そんな時に役立つのが、特定の文字列のパターンを扱える「正規表現(せいきひょうげん)」と、それを利用した関数です。複雑な条件の検索や抽出、置換を一瞬で終わらせることができます。
本記事では、正規表現が使えるスプレッドシート関数 REGEXMATCH、REGEXEXTRACT、REGEXREPLACE の3つを、実際の業務で使えるサンプルを交えながら分かりやすく解説します。
この記事を読み終える頃には、面倒なデータクレンジング(データ整形)作業を自動化し、業務効率を格段にアップさせるスキルが身についているはずです。
※正規表現についての詳しい解説は、こちらの記事をご覧ください。
Googleスプレッドシートで正規表現が使える代表的な3つの関数
それでは、正規表現を使ってデータ処理を行うための代表的な3つの関数を見ていきましょう。
| 関数名 | 機能 | こんな時に便利! |
| REGEXMATCH | 文字列が特定のパターンに一致するかを判定する | メールアドレスの形式が正しいかチェックしたい |
| REGEXEXTRACT | 文字列から特定のパターンに一致する部分を抜き出す | 住所データから市区町村だけを抽出したい |
| REGEXREPLACE | 文字列の特定のパターンに一致する部分を置き換える | データに含まれる不要な記号や補足情報を一括削除したい |
これら3つの関数を使いこなすことで、手作業で行っていた多くのデータ整理業務を自動化できます。次から、それぞれの関数の使い方を具体的なビジネスシーンの例と共に解説していきます。
【実践1】REGEXMATCH関数
REGEXMATCH関数は、指定したセル(テキスト)が、正規表現のパターンに一致するかどうかを判定し、一致すればTRUE(真)、一致しなければFALSE(偽)を返す関数です。
基本的な構文
=REGEXMATCH(
テキスト,
正規表現
)- テキスト:検索対象のセルまたは文字列を指定します。
- 正規表現:検索したい文字列のパターンを正規表現で指定します。
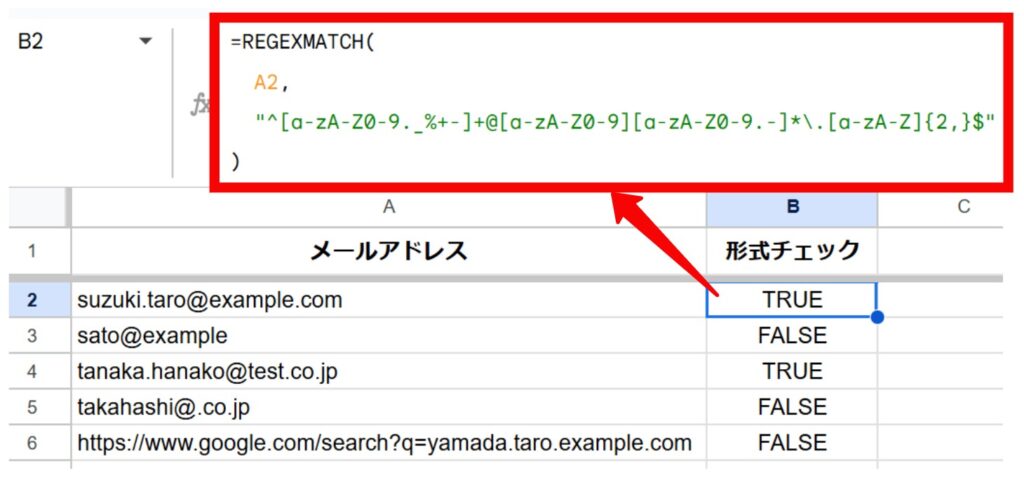
活用例1:メールアドレスの形式をチェックする
顧客リストにあるメールアドレスが、一般的な形式(例:example@domain.com)に沿っているかを確認します。
状況:
A列に顧客のメールアドレスが入力されています。中には@が抜けていたり、ドメインがなかったりする無効なアドレスが混じっています。

関数式:
=REGEXMATCH(
A2,
"^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9][a-zA-Z0-9.-]*\.[a-zA-Z]{2,}$"
)結果:
メールアドレスとして正しい形式のものはTRUE、そうでないものはFALSEと表示されます。これにより、無効なアドレスを簡単に見つけ出すことができます。
関数の解説:
少し複雑に見えますが、この正規表現は「@の前後に適切な文字があり、最後に.(ドット)と2文字以上のアルファベット(.comや.co.jpなど)がある」というメールアドレスの一般的なパターンを表現しています。このパターンに一致するかどうかをREGEXMATCH関数が判定しています。
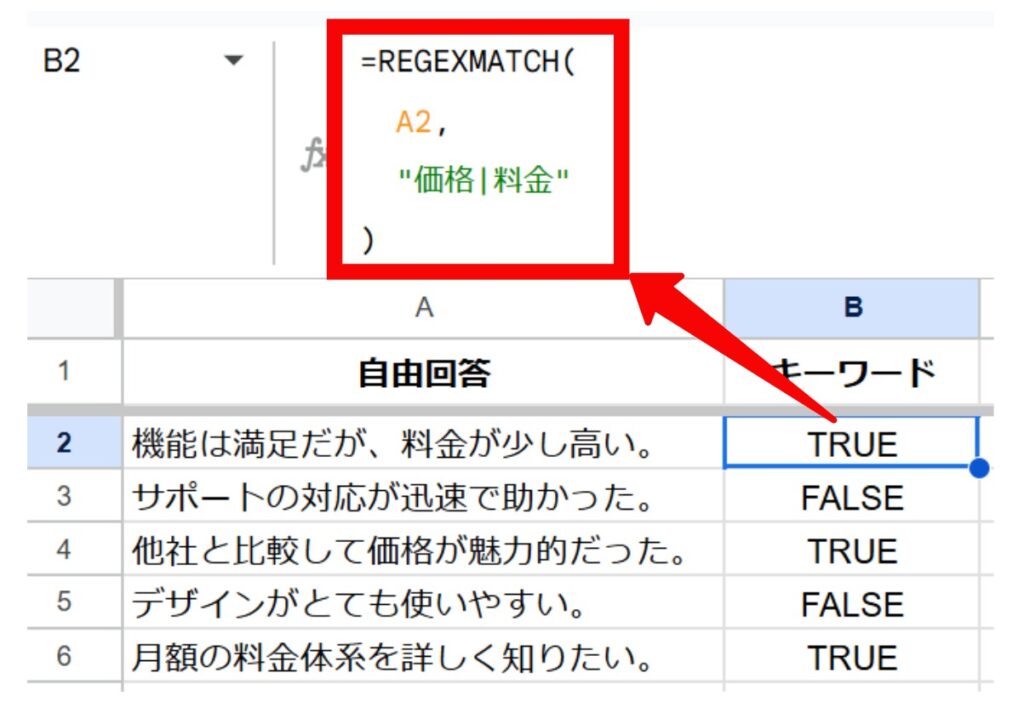
活用例2:アンケートの回答から特定のキーワードを探す
アンケートの自由回答欄から、特定のキーワード(例:「価格」「料金」)が含まれている回答を抽出したい場合に便利です。
状況:
A列にサービスの満足度に関する自由回答が入力されています。価格に関する意見を分析するため、「価格」または「料金」という単語が含まれる回答をピックアップします。

関数式:
=REGEXMATCH(
A2,
"価格|料金"
)結果:
回答文に「価格」または「料金」のいずれかの単語が含まれていればTRUE、含まれていなければFALSEが返されます。FILTER関数と組み合わせれば、TRUEの行だけを絞り込んで表示することも可能です。
関数の解説:
正規表現の|(パイプライン)は、「または(OR)」を意味します。これにより、”価格|料金”は「”価格”または”料金”」というパターンになり、どちらかの単語に一致すればTRUEを返すようになります。
【実践2】REGEXEXTRACT関数
REGEXEXTRACT関数は、指定したセル(テキスト)から、正規表現のパターンに一致した部分だけを抜き出して(抽出して)表示する関数です。
基本的な構文
=REGEXEXTRACT(
テキスト,
正規表現
)- テキスト:抽出対象のセルまたは文字列を指定します。
- 正規表現:抽出したい文字列のパターンを正規表現で指定します。
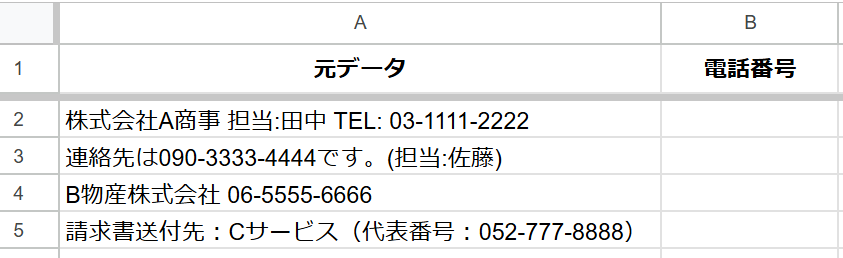
活用例1:様々な形式のデータから電話番号だけを抽出する
会社名や担当者名などが混在したセルから、電話番号だけを正確に抜き出します。
状況:
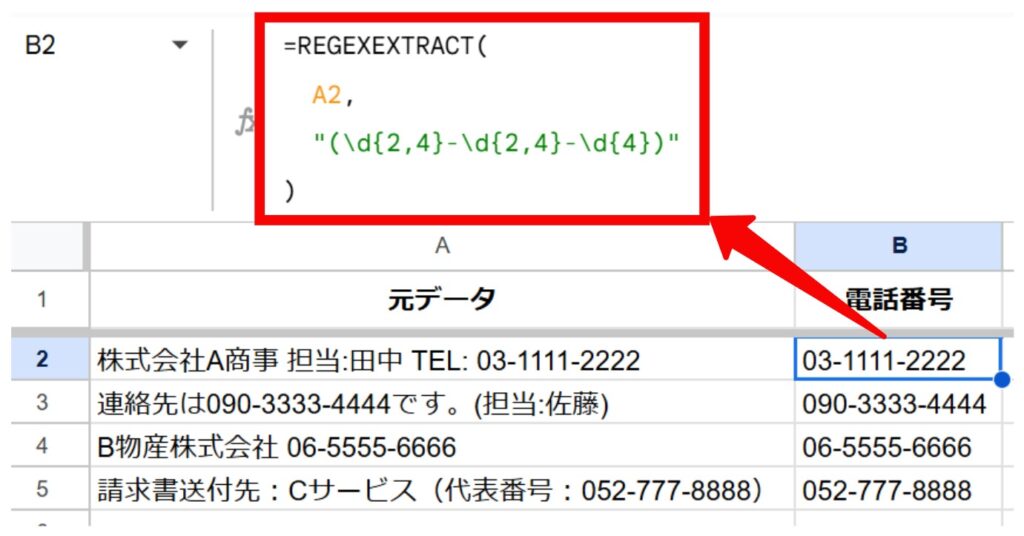
A列に「株式会社〇〇 担当:鈴木 TEL: 03-1234-5678」のように、様々な情報が入力されています。この中から電話番号の部分だけをB列に抽出します。
関数式:
=REGEXEXTRACT(
A2,
"(\d{2,4}-\d{2,4}-\d{4})"
)結果:
A列の文字列から、電話番号のパターンに一致する部分だけがB列に抽出されます。
関数の解説:
\dは「任意の数字」、{2,4}は「直前の文字が2回から4回繰り返す」ことを意味します。全体で「数字が2〜4桁、ハイフン、数字が2〜4桁、ハイフン、数字が4桁」という日本の電話番号でよく使われるパターンを表現しています。
正規表現を()(丸括弧)で囲むことで、そのパターンに一致した部分を抽出対象として指定しています。
活用例2:商品コードから特定の情報(製造年)を抜き出す
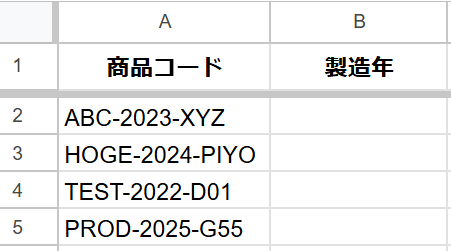
「ABC-2024-XYZ」のような構造化された商品コードから、特定の部分だけを取り出します。
状況:
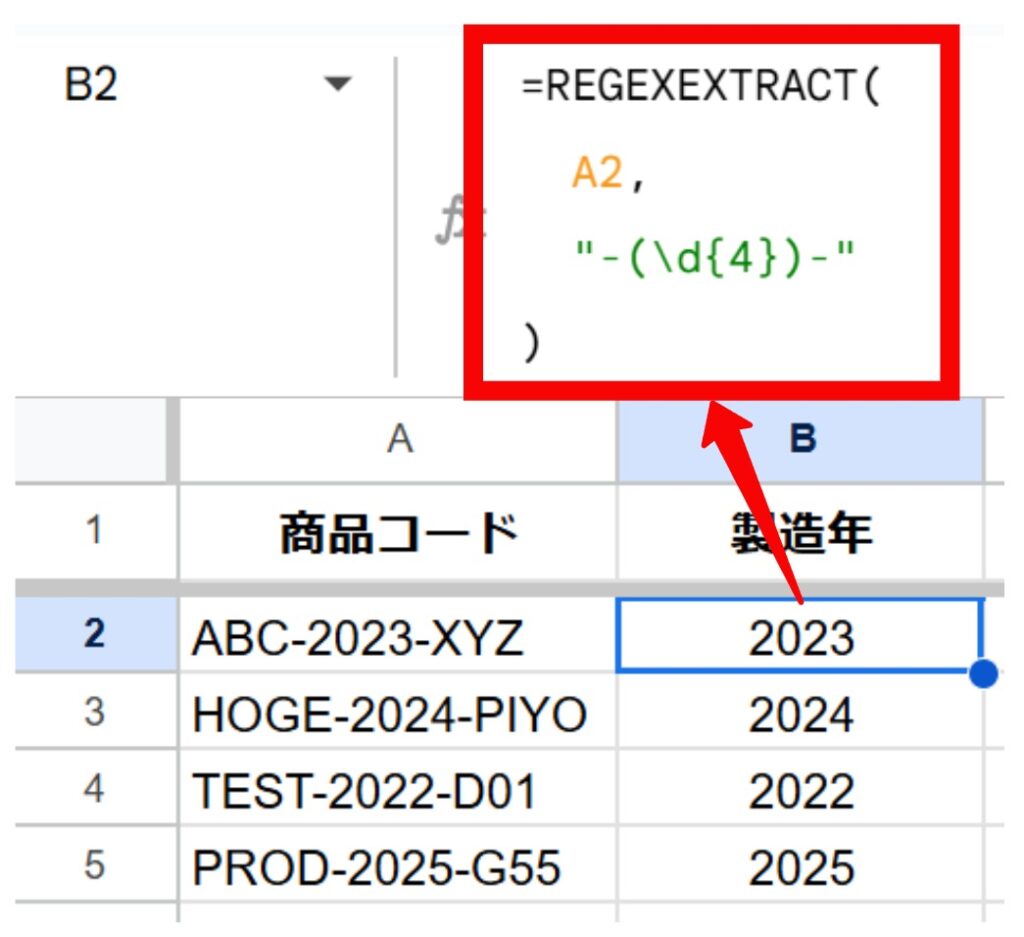
A列に[カテゴリ]-[製造年]-[製品番号]という形式の商品コードが並んでいます。このコードから「製造年」にあたる4桁の数字だけを抜き出したいと考えています。
関数式:
=REGEXEXTRACT(
A2,
"-(\d{4})-"
)結果:
商品コードのハイフンに挟まれた4桁の数字(製造年)がB列に抽出されます。
関数の解説:
\d{4}は「数字が4回続く」ことを意味します。その前後をハイフンで挟むことで、-[4桁の数字]-というパターンを指定しています。この場合も()で囲んだ\d{4}の部分だけが抽出結果として返されます。
【実践3】REGEXREPLACE関数
REGEXREPLACE関数は、指定したセル(テキスト)内で、正規表現のパターンに一致した部分を、別の文字列に置き換える関数です。
基本的な構文
=REGEXREPLACE(
テキスト,
正規表現,
置換後のテキスト
)- テキスト:置換対象のセルまたは文字列を指定します。
- 正規表現:置換したい文字列のパターンを正規表現で指定します。
- 置換後のテキスト:パターンに一致した部分を、ここで指定した文字列に置き換えます。空欄にしたい場合は””と入力します。
活用例1:データ内の補足情報(括弧書き)を一括で削除する
SUBSTITUTE関数では対応が難しい、内容が異なる括弧書きの情報を一括で削除します。
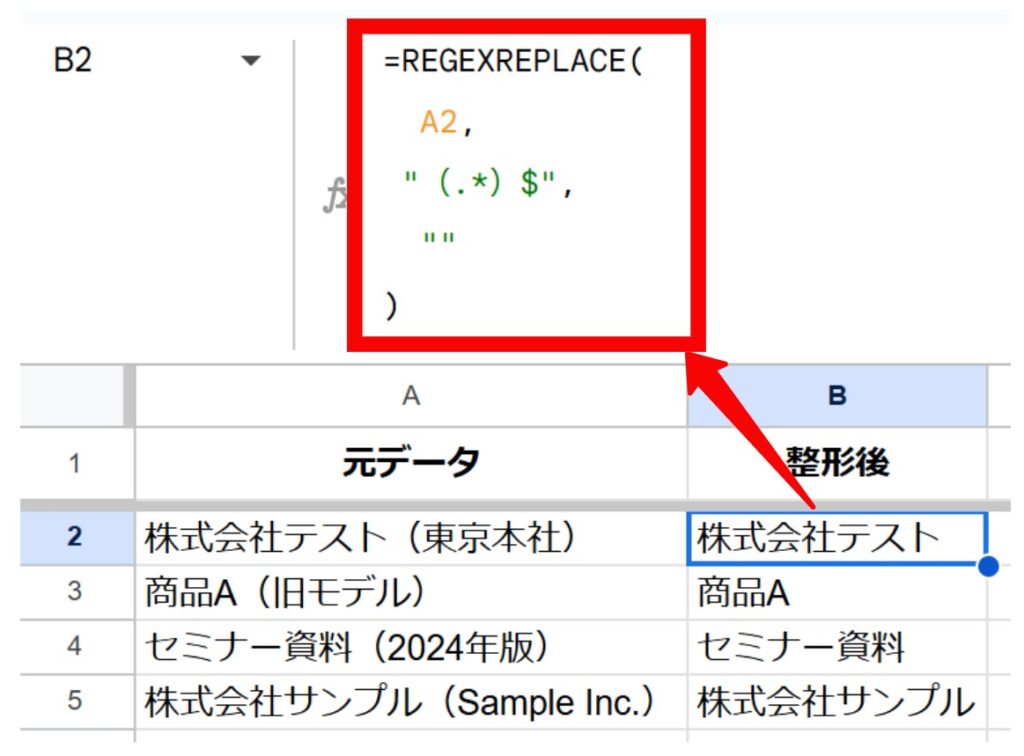
状況:
A列に会社名や商品名が入力されていますが、「株式会社テスト(東京本社)」「商品A(旧モデル)」のように、括弧で補足情報が追記されています。データの名寄せや集計のために、これらの括弧と括弧内の文字をすべて削除します。

関数式:
=REGEXREPLACE(
A2,
"(.*)$",
""
)※全角の()を対象としています。半角の()を削除したい場合は、正規表現を”\(.*\)$”とします。
結果:
括弧と括弧の中に書かれていた文字がすべて削除されます。
関数の解説:
「(で始まり、)で終わる、任意の一文字(.)が0回以上繰り返す(*)末尾の文字列」を意味します。これにより、括弧の中の文字数や内容に関わらず、パターンに一致する部分をすべて””(空の文字列)に置き換えることができます。
活用例2:氏名から敬称(「様」など)を削除する
顧客名の末尾についている敬称を一括で取り除き、氏名だけのデータを作成します。
状況:
A列に「田中 太郎 様」や「佐藤 花子 御中」のように、氏名と敬称がセットで入力されています。DMの宛名ラベルなどで氏名だけを使いたい場合に、敬称を削除します。
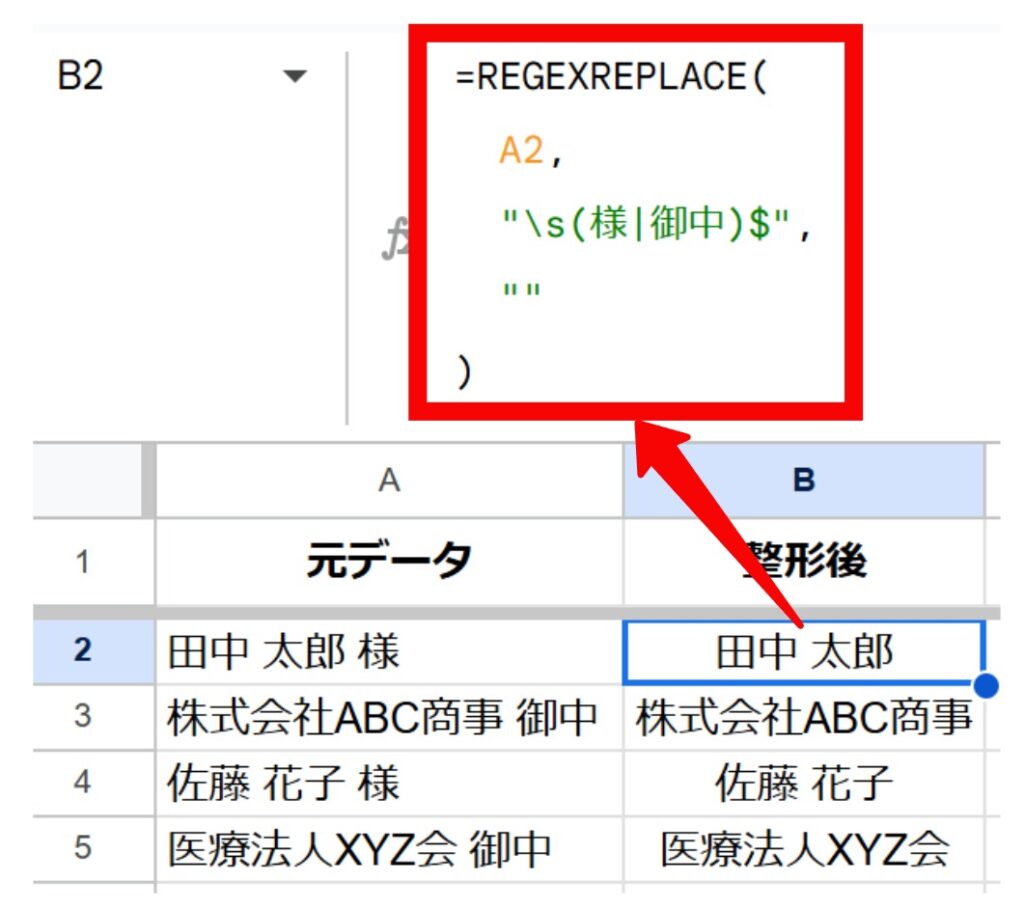
関数式:
=REGEXREPLACE(
A2,
"\s(様|御中)$",
""
)※氏名と敬称の間に半角スペースがあることを想定しています。
結果:
氏名の後ろにある半角スペースと敬称(「様」または「御中」)がまとめて削除され、氏名だけのデータがB列に表示されます。
関数の解説:
「行の末尾($)にある、” 半角スペース(\s)様” または ” 半角スペース(\s)御中”」というパターンに一致した部分を、””(空の文字列)に置き換えています。
まとめ:正規表現を味方につけて、データ仕事の達人へ
今回は、Googleスプレッドシートで正規表現が使える3つの便利な関数、REGEXMATCH、REGEXEXTRACT、REGEXREPLACEをご紹介しました。
- REGEXMATCH:パターンに合うかチェック
- REGEXEXTRACT:パターンに合う部分を抜き出す
- REGEXREPLACE:パターンに合う部分を置き換える
最初は正規表現の書き方に戸惑うかもしれませんが、よく使うパターンは限られています。本記事で紹介したようなビジネスシーンで使えるサンプルをコピーして少し書き換えることから始めてみてください。
正規表現を使いこなせれば、これまで手作業で何時間もかかっていたデータクレンジングや集計作業が、数式一つで完了するようになります。ぜひ、あなたのスプレッドシート業務に正規表現を取り入れて、作業効率を劇的に改善してみてください!
※Googleサービスは、Google LLC の商標であり、この記事はGoogleによって承認されたり、Google と提携したりするものではありません。