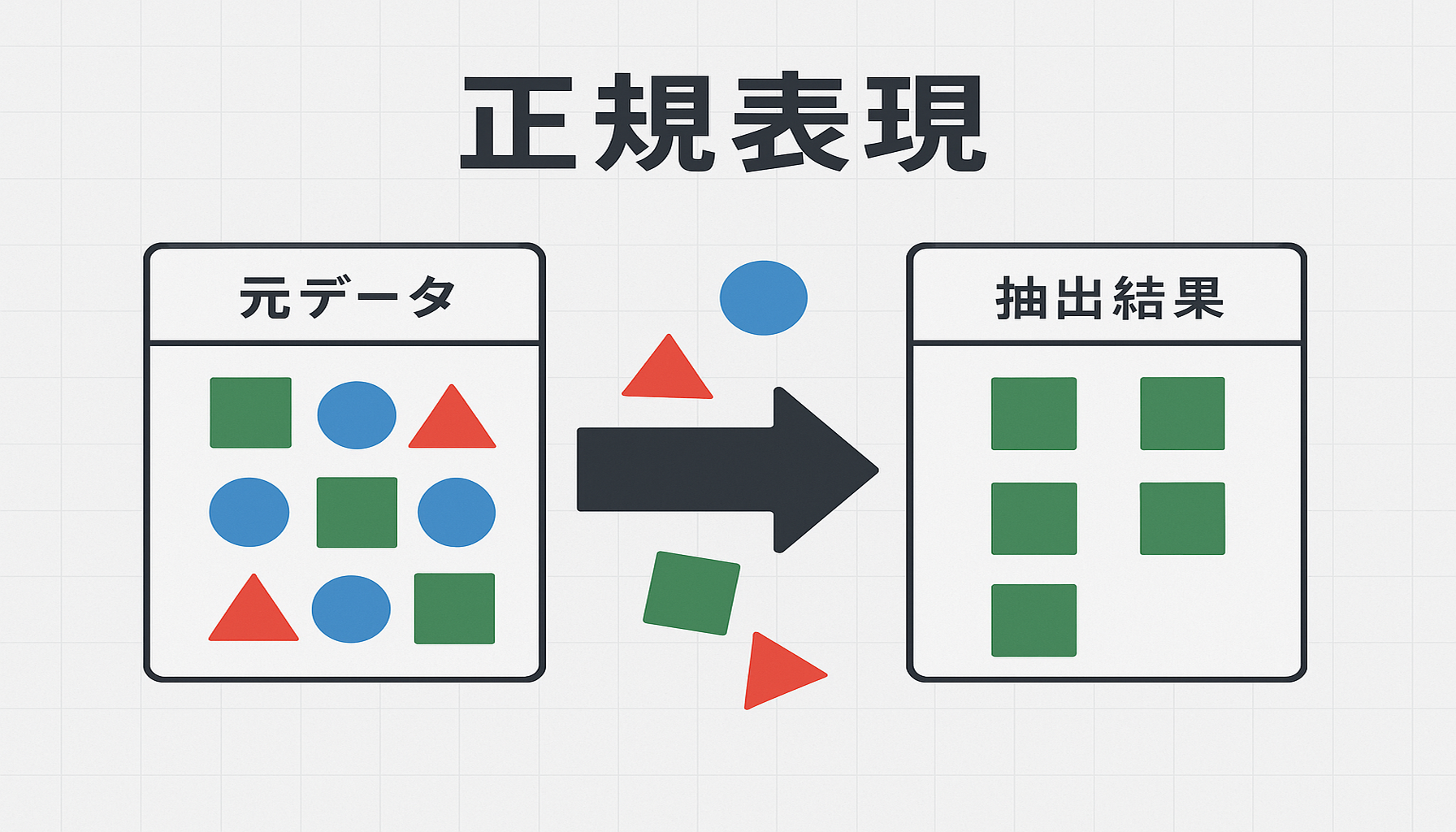
「大量の顧客リストから、電話番号だけを抜き出したい…」
「入力形式がバラバラな住所データを、きれいに整形したい…」
「特定のキーワードを含む商品コードだけを、効率よく検索したい…」
日々の業務で、このようなテキストデータの扱いに頭を悩ませてはいませんか?
Excelやスプレッドシートの関数を少し使えるようになったけれど、もっと複雑な条件でデータを整理したり、抽出したりするには、一つひとつ手作業で修正するしかなく、時間がかかってしまう…。
もし、そんなお悩みを抱えているなら、「正規表現(せいきひょうげん)」があなたの強力な武器になるかもしれません。
「正規表現」という言葉自体、初めて聞く方も多いかもしれません。これは一部の専門家だけが使う難しいものではなく、基本的なルールさえ覚えてしまえば、まるでExcelの関数の延長線上のような感覚で、複雑なテキスト操作を自動化できる便利な道具なのです。
この記事では、専門的な知識がない方でもつまずかないよう、正規表現の基本をゼロから丁寧に解説します。身近な業務で使える具体例を交えながら、一歩ずつ学んでいきましょう!
※すぐに一覧を見たい方は、記事の最後にある「正規表現メタ文字一覧」をご覧ください。
正規表現とは?
正規表現(Regular Expression)とは、一言でいうと「様々な文字列のパターンを表現するための、世界共通の書き方のルール」です。
例えば、パソコンでファイルを探すときに「*」(アスタリスク)を使ったことはありませんか?これはワイルドカード(色々な文字の代わりになる特殊な記号)の一種で、「議事録*.xlsx」と検索すれば、「議事録20230401.xlsx」や「議事録A社定例.xlsx」などがヒットしますよね。
正規表現は、このワイルドカードをさらに強力にしたもの、とイメージしてください。「3桁の数字-4桁の数字」というパターンや、「〇〇@〇〇.co.jp」というメールアドレスのパターンなどを、短い記号の組み合わせで表現できます。
正規表現で何ができるの?ビジネスシーンでの活用例
正規表現をマスターすると、手作業で行っていた面倒なテキスト処理を、一瞬で完了させることができます。
- 検索・抽出(マッチング):大量のデータの中から、特定のパターンに一致する文字列だけを探し出す。
- 例:顧客リストから電話番号や郵便番号だけをすべて抜き出す。
- 例:アンケートの自由回答欄から、特定の製品名が含まれる回答だけを抽出する。
- 置換:特定のパターンの文字列を、別の文字列に置き換える。
- 例:全角で入力された電話番号の数字を、すべて半角に統一する。
- 例:個人情報保護のため、メールアドレスの「@」より前を「*」に置き換える。
- 分割:特定のルールに基づいて、一つの文字列を複数の要素に分割する。
- 例:「東京都千代田区丸の内1-1-1」という住所を、「東京都」「千代田区」「丸の内1-1-1」に分割する。
- 入力チェック(バリデーション):ユーザーが入力したデータが、決められた形式に沿っているかを確認する。
- 例:会員登録フォームで、メールアドレスやパスワードの形式が正しいかチェックする。
これらの作業を自動化できれば、業務効率が劇的に向上し、入力ミスなどのヒューマンエラーも防ぐことができます。
正規表現はどこで使えるの?
正規表現は、実は私たちの身近なツールに数多く搭載されています。
- テキストエディタ:高機能なエディタ(例:サクラエディタ、Visual Studio Codeなど)の多くは、正規表現を使った検索・置換機能を備えています。
- オフィスソフト:Googleスプレッドシートなどでも、関数や検索機能の一部として正規表現を利用できます。
- 各種システム開発ツール:より専門的な話になりますが、Webサイトやアプリケーションを開発する際には、ほぼ標準的な機能として利用されています。
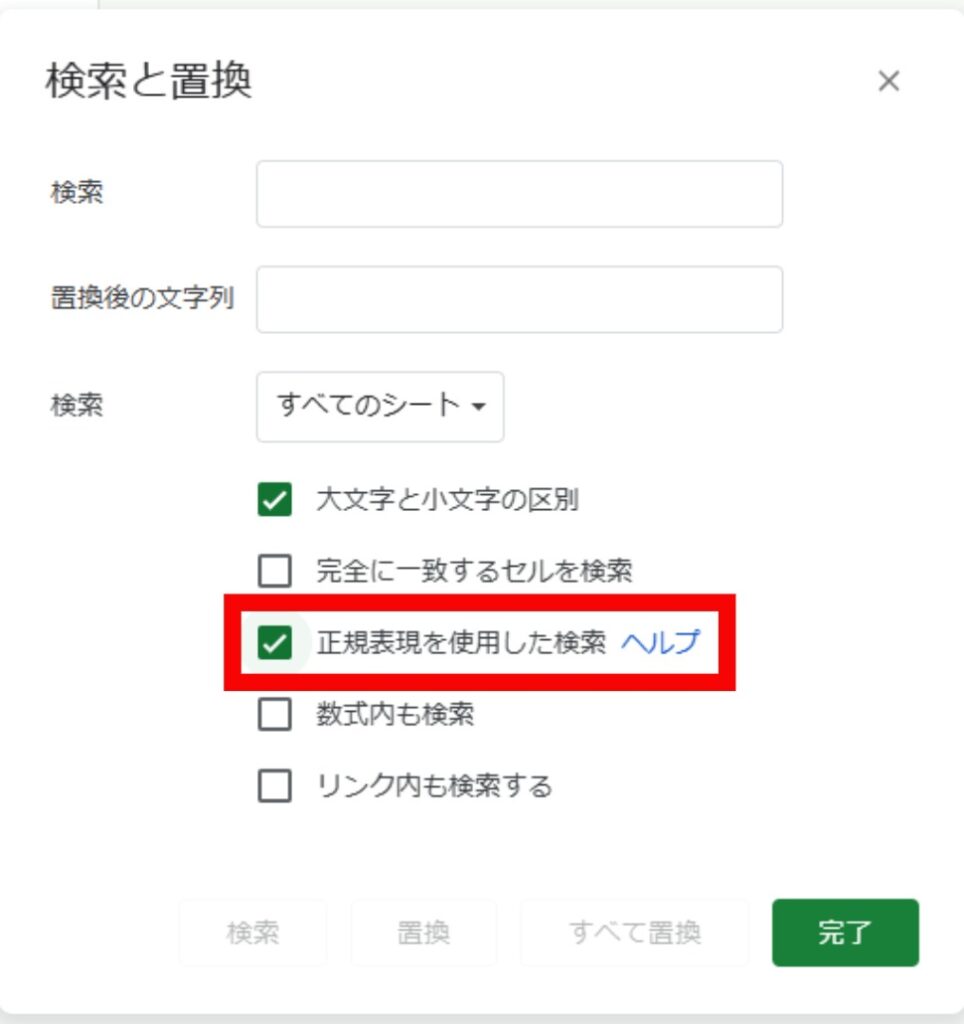
普段お使いのツールにも、設定を切り替えるだけで使える正規表現機能が隠れているかもしれません。まずは、ツールの「検索」や「置換」のダイアログに、「正規表現を使用する」といったチェックボックスがないか探してみるのがおすすめです。
これだけは覚えたい!正規表現の基本ルール(メタ文字)
それでは、いよいよ正規表現の基本的なルールを学んでいきましょう。
正規表現で使われる特殊な意味を持つ記号のことを「メタ文字」と呼びます。ここでは、業務で特によく使う重要なメタ文字を厳選してご紹介します。
Step 1: 1文字にマッチさせる記号
まずは、特定の「1文字」を表す基本のメタ文字です。
| メタ文字 | 意味 | ビジネスでの使用例 |
| . | 任意の1文字(改行以外) | 商品コード「A-01」「A-B1」などをA-.1で検索 |
| \d | 任意の数字1文字([0-9]と同じ) | 電話番号や郵便番号など、数字が含まれるデータの検索 |
| \w | 任意の英数字1文字([a-zA-Z0-9_]と同じ) | 会員IDや製品型番など、英数字で構成されるデータの検索 |
| \s | スペースやタブなどの空白文字1文字 | 姓と名の間にあるスペース「田中 太郎」などを検索 |
| [] | 角括弧内のいずれか1文字 | [ab]はaかbにマッチ。[0-9]は0〜9の数字にマッチ |
Step 2: 繰り返しの回数を指定する記号(量指定子)
特定の文字やパターンが何回繰り返すかを指定します。これを「量指定子(りょうしていし)」と呼びます。
| メタ文字 | 意味 | ビジネスでの使用例 |
| * | 直前の文字が0回以上繰り返し | ab*c は ac, abc, abbc にマッチ |
| + | 直前の文字が1回以上繰り返し | ab+c は abc, abbc にマッチ(acにはマッチしない) |
| ? | 直前の文字が0回または1回 | ab?c は ac, abc にマッチ(abbcにはマッチしない) |
| {n} | 直前の文字がちょうどn回繰り返し | \d{3} は3桁の数字(例:123)にマッチ |
| {n,} | 直前の文字がn回以上繰り返し | \d{7,} は7桁以上の数字にマッチ |
| {n,m} | 直前の文字がn回以上m回以下の繰り返し | \d{2,4} は2〜4桁の数字にマッチ |
Step 3: 文字列の位置を指定する記号(アンカー)
行の先頭や末尾など、特定の位置を指定するメタ文字です。これを「アンカー」と呼びます。
| メタ文字 | 意味 | ビジネスでの使用例 |
| ^ | 行の先頭 | ^A は行の先頭がAで始まる行にマッチ |
| $ | 行の末尾 | Z$ は行の末尾がZで終わる行にマッチ |
Step 4: 特殊な文字を「ただの文字」として扱う(エスケープ)
ここまで、. や * などの文字が特殊な意味を持つことを学びました。では、ファイル名に含まれる「.」(ドット)や、注釈で使う「*」(アスタリスク)そのものを検索したい場合はどうすればよいでしょうか。
このような場合は、「これは特殊な意味を持つ文字ではなく、ただの文字として扱ってください」という合図を送る必要があります。この操作を「エスケープ」と呼びます。
エスケープの方法は簡単で、特殊な意味を持つ文字の直前に「\」(円マークまたはバックスラッシュ)を置くだけです。
| 検索したい文字 | 正規表現での書き方 | 説明 |
| . (ドット) | \. | . は「任意の1文字」という意味なので、\でエスケープします。 |
| * (アスタリスク) | \* | * は「0回以上の繰り返し」という意味なので、\でエスケープします。 |
| ? (クエスチョンマーク) | \? | ? は「0回か1回の繰り返し」という意味なので、\でエスケープします。 |
| ( や ) (括弧) | \( \) | () は「グループ化」という意味なので、\でエスケープします。 |
| \ (円マーク/バックスラッシュ) | \\ | \ 自体を検索したい場合は、\を2つ続けます。 |
例えば、テキスト中にある (A社) という文字列を正確に見つけたい場合、正規表現は \(A社\) となります。
【実践演習】ビジネスデータで正規表現を使ってみよう
それでは、これまで学んだメタ文字を組み合わせて、より実践的なデータ抽出に挑戦してみましょう。ここではGoogleスプレッドシートの「検索と置換」機能を使う場面を想定します。
演習1:郵便番号を抽出する
「〒100-0005 東京都千代田区丸の内」というデータから、郵便番号「100-0005」だけを見つけ出してみましょう。 日本の郵便番号は「3桁の数字 – 4桁の数字」というパターンです。
これを正規表現で表すと \d{3}-\d{4} となります。
- \d{3} → 数字が3回繰り返し
- – → ハイフン
- \d{4} → 数字が4回繰り返し

演習2:様々な形式の電話番号を抽出する
顧客リストには、090-1234-5678(ハイフンあり)や 09012345678(ハイフンなし)といった形式が混在していることがあります。これらの電話番号をまとめて見つけるにはどうすればよいでしょうか。
正規表現の書き方例: \d{2,4}-?\d{2,4}-?\d{4}
- \d{2,4} : 2〜4桁の数字(市外局番や携帯電話の先頭部分)。
- -? : – が0回または1回出現。つまり、ハイフンがあってもなくても良い。
この正規表現を使えば、ハイフンの有無にかかわらず、電話番号らしい数字の並びを効率的に探し出すことができます。
【発展】さらに高度なパターン指定(先読み・後読み)
基本をマスターしたら、少し発展的なテクニックも見てみましょう。「先読み(さきよみ)」「後読み(あとよみ)」は、特定の文字列の「前」や「後」に、ある特定のパターンが存在するかどうかをチェックできる機能です。
これは「マッチはさせたいけど、結果には含めたくない」という、少し複雑な条件を指定したいときに役立ちます。
具体例:「円」という文字の直前にある数字だけを抜き出す
商品A 1,500円 商品B 2000円 商品C 3,800円
上記のデータから、価格の「数字部分だけ」を抜き出したいとします。しかし、単純に \d+ などで検索すると、他の無関係な数字までヒットしてしまうかもしれません。
ここで「先読み」を使うと、「『円』という文字が直後にある、1つ以上の数字の並び」という条件を指定できます。
正規表現の書き方例: \d[\d,]+(?=円)
- \d[\d,]+ : 1つ以上の数字(カンマ区切りを含む)。
- (?=円) : ここが「先読み」の部分。「直後に『円』という文字がある」という条件を指定しています。
この正規表現を使うと、1,500 2000 3,800 の数字部分だけがマッチし、条件として使った「円」の文字自体は結果に含まれません。非常に便利ですが、少し複雑なため、まずはこういう機能もある、と覚えておくだけで十分です。
注意点:プラットフォームによる「方言」の違い
ここで一つ注意点があります。実は、正規表現には「方言」のようなものが存在し、使用するツールによって、使えるメタ文字が微妙に異なる場合があります。
例えば、発展でご紹介した「後読み・先読み」は、ツールによって対応していない代表的な機能です。
具体例:特定の目印の前後の文字列を取得したい場合
ID:12345 (田中) というテキストを例に考えてみましょう。
ケース1:「ID:」より後ろの「12345 (田中)」を取得したい
- 使えない書き方(後読み): (?<=ID:).*
- 「ID:という文字列の直後から、行の末尾まで」を意味しますが、後読み (?<=パターン) はGoogleスプレッドシートの関数などでは使えません。
- 使える書き方(代替案): ID:(.*)
- これは「ID:という文字列に続いて、何かしらの文字列が行の末尾まで続く」という意味です。REGEXEXTRACTのような関数と組み合わせることで、カッコ(グループ)にマッチした 12345 (田中) の部分だけを抜き出せます。
ケース2:「(田中)」より前の「ID:12345 」を取得したい
- 使えない書き方(先読み): .*(?=\(田中\))
- 「行の先頭から、(田中)という文字列の直前まで」を意味しますが、これも先読み (?=パターン) を使うため、ツールによっては利用できません。
- 使える書き方(代替案): ^(.*?)\(田中\)
- これは「行の先頭(^)から、なるべく短い文字列(.*?)が続き、その後に (田中) が来る」という意味です。ケース1と同様に、カッコの部分 ID:12345 だけを抜き出すことができます。
このように、同じ目的でもツールによって書き方が変わることがあります。もし、使いたい正規表現がうまく動かない場合は、「(使いたいツール名) 正規表現 (やりたいこと)」といったキーワードで検索し、そのツールで使える書き方を確認してみるのが良いでしょう。
まとめ:正規表現はデータ活用の第一歩
今回は、正規表現の基本的な考え方と、ビジネスシーンで役立つメタ文字について解説しました。
- 正規表現とは、文字列のパターンを表現するためのルール
- メタ文字(特殊な記号)を組み合わせてパターンを作成する
- データ抽出、置換、入力チェックなど、様々な業務を自動化できる
- まずは身近なテキストエディタやスプレッドシートで試してみるのがおすすめ
最初は見慣れない記号に戸惑うかもしれませんが、パズルを解くような感覚で試しているうちに、すぐに慣れていくはずです。正規表現を使いこなせれば、これまで手作業で何時間もかかっていたデータクレンジング作業が、ほんの数分で終わるかもしれません。
ぜひ活用してみてください!
正規表現メタ文字一覧
| メタ文字 | 名称 | 意味 |
| . | 任意の一文字 | 任意の1文字(改行以外) |
| \d | 数字 | 任意の数字1文字([0-9]と同じ) |
| \D | 非数字 | 数字以外の任意の1文字 |
| \w | 単語構成文字 | 任意の英数字とアンダースコア([a-zA-Z0-9_]と同じ) |
| \W | 非単語構成文字 | 英数字とアンダースコア以外の任意の1文字 |
| \s | 空白文字 | スペースやタブなどの空白文字1文字 |
| \S | 非空白文字 | 空白文字以外の任意の1文字 |
| [] | 文字クラス | 角括弧内のいずれか1文字(例: [abc]はa,b,cのいずれか) |
| [^] | 否定文字クラス | 角括弧内にない、いずれか1文字(例: [^abc]はa,b,c以外) |
| ^ | 行頭 | 行の先頭 |
| $ | 行末 | 行の末尾 |
| \b | 単語境界 | 単語の先頭または末尾 |
| * | 0回以上の繰り返し | 直前の文字またはグループが0回以上繰り返し |
| + | 1回以上の繰り返し | 直前の文字またはグループが1回以上繰り返し |
| ? | 0回または1回の繰り返し | 直前の文字またはグループが0回または1回 |
| {n} | n回の繰り返し | 直前の文字またはグループがちょうどn回繰り返し |
| {n,} | n回以上の繰り返し | 直前の文字またはグループがn回以上繰り返し |
| {n,m} | n回以上m回以下の繰り返し | 直前の文字またはグループがn回以上m回以下の繰り返し |
| () | グループ化 | 複数のパターンをグループ化し、後から参照できるようにする |
| | | いずれか(OR) | A|B のように書き、AまたはBのいずれかにマッチ |
※Googleサービスは、Google LLC の商標であり、この記事はGoogleによって承認されたり、Google と提携したりするものではありません。